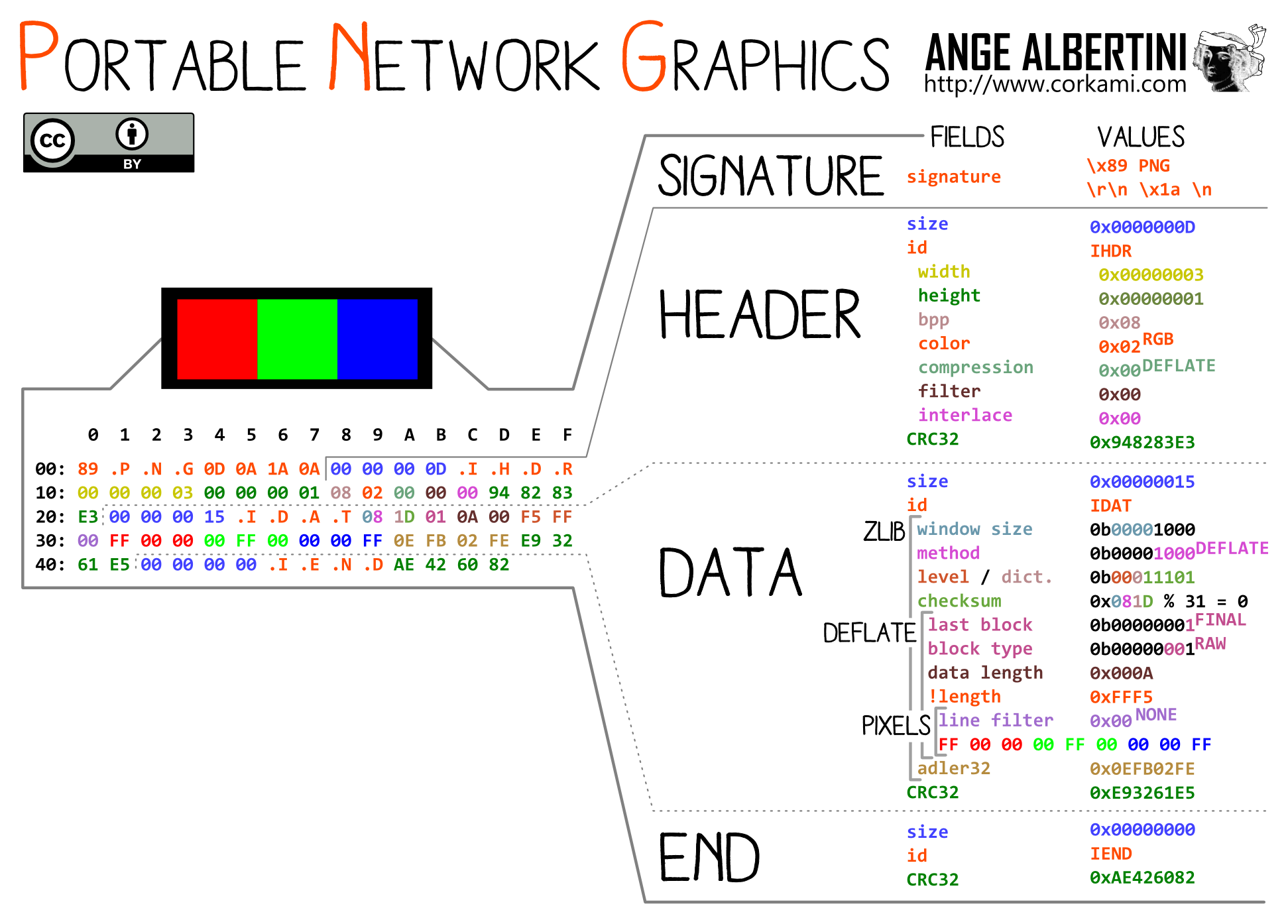
Size: I don’t think that’s a problem.
It’s Metadata. With todays “default” storage capacities: trivial.
The payload is currently stored already - so that has to work
anyways.
The Metadata is also currently stored (in databases/files,
etc).
Even if you keep/accumulate Metadata for a longer period: It’s still
Metadata(-sizes).
Okay… I propose storing metadata as binary-proof UTF-8 encoded
strings/text. Even numbers. For starters. That might increase storage
demands by “blowing up” long numbers (16, 32, 64 word-size (bits), for
example) into “way larger” strings. Yet, if we can “afford” this “waste”
of digital storage space, imagine you could see/read any information as
plaintext by default.
Or maybe the metadata layout can indeed by declared like a
programming code Object (instead of a SQL-table design). Like “Class”
definitions per Data Object Types? Then numbers could be
integer/long/etc data types. And strings could even be active methods.
;)
Speed: Speed could indeed be a major factor.
However, I still think that any performance “Einbußen”, compared to
now are still worth investigating on how to make things faster.
For now, I propose the same technology that is used for indexing
websites (and even locally stored files - in different formats). All
this already exists, and is widely in use - even by “smaller” websites.
So it can’t be that hard. And hardware is still cheaper than manpower
and life- and braintime.
Also, any application that has its own kind of “library”
database/config stored somewhere, is already performing these tasks
sufficiently. Initial indexing of existing contents takes a while, but
then, only changes are monitored - and that doesn’t even bother nowadays
“average” computer systems.
Maybe it’d drain a bit more on battery-powered systems. But hey, I’ve
heard they’re working on “batterifying” everything by 2020. Or some
other horizon.
On the other hand: Considering, that with Data Objects, less
individual code-libraries will need to be used (to access metadata, and
provide library-functionality, etc). And since this filesystem provides
basic functionality by default, there’d be less code necessary to run
(and use resources).
How large the impact of this could be, and how far in the future, the
coverage and support to speak of “real world tested” is unclear at the
moment.
Interoperability:
Would be greatly improved. I’m quite serious about this. Most of my
work in the last 20+ years was: Making things interoperable, and improve
upon existing technologies and possibilities.
With files becoming Objects - and Metadata “accumulating” along its
payload, becoming well-annotated (semi-automatically) and therefore
(more) self-sustaining and easier (re-)usable.
Imagine all “future” applications to simply provide tagging and
filtering options, optimized UI for different use cases. Music Browser,
Video & Film Browser, Document Browser, etc - IIIF-design by
default.
By proposing serious usage of Metadata on any kind of Digital Object
(Collection) - from personal to professional, small to large scale: We
archivists can now pimp the computing world, by applying our decades of
real “META-EXPERIENCE FU” knowledge and skills.